Processes and Threads (1)
프로세스와 쓰레드?
컴퓨터는 다양한 연산을 동시에 수행하는 것처럼 보입니다. 그런데 하나의 CPU를 가진 컴퓨터 시스템은, 어떤 시점 t0에서 한가지의 연산밖에 수행하지 못합니다. 그러면 어떻게 동시에 수행하는 것처럼 보일까요? 프로세스와 쓰레드를 이용해 그렇게 구현할 수 있습니다. 프로세스는 실행하는 주체로, 자원을 할당받습니다. 단, 여기서 운영체제는 프로세스가 아닌 coda data임에 유의합니다. 쓰레드는 프로세스의 각각의 실행 흐름을 의미합니다.
프로세스 모델
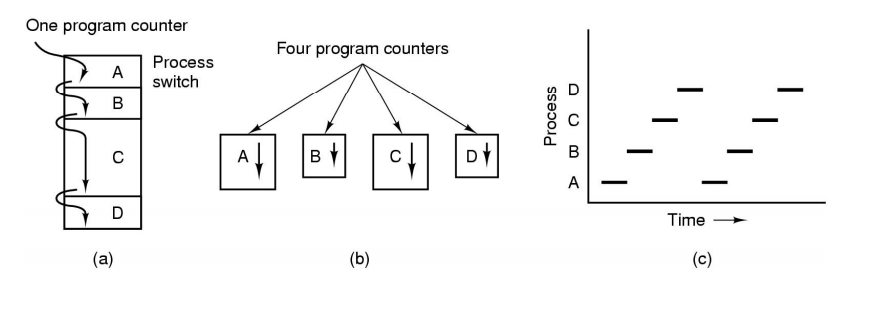
다음 그림을 보면, (a)는 4개 프로그램의 멀티프로그래밍 과정을 설명하고 있고, (b)는 각각 프로그램들이 독립되어 실행되는 프로세스의 개념, (c)는 하나의 프로그램은 동시에 실행될 수 없음을 보입니다.

이 그림처럼 어떤 프로세스를 실행중 (5000~) Time out으로 타이머 인터럽트를 만나게 되면 해당 인터럽트 서비스 루틴 (100~)으로 넘어가게 되고, 스케줄러는 어떤 우선순위에 따라 다음 프로세스 (8000~)로 넘어갑니다. 또 I/O request의 입출력 인터럽트를 만나게 되면 해당 인터럽트 서비스 루틴으로… 해당 과정이 반복됩니다. 그러면서 우리는 프로그램을 동시에 실행시키는것처럼 보이게 됩니다.
프로세스와 쓰레드?
컴퓨터는 다양한 연산을 동시에 수행하는 것처럼 보입니다. 그런데 하나의 CPU를 가진 컴퓨터 시스템은, 어떤 시점 t0에서 한가지의 연산밖에 수행하지 못합니다. 그러면 어떻게 동시에 수행하는 것처럼 보일까요? 프로세스와 쓰레드를 이용해 그렇게 구현할 수 있습니다. 프로세스는 실행하는 주체로, 자원을 할당받습니다. 단, 여기서 운영체제는 프로세스가 아닌 coda data임에 유의합니다. 쓰레드는 프로세스의 각각의 실행 흐름을 의미합니다.
프로세스 모델
다음 그림을 보면, (a)는 4개 프로그램의 멀티프로그래밍 과정을 설명하고 있고, (b)는 각각 프로그램들이 독립되어 실행되는 프로세스의 개념, (c)는 하나의 프로그램은 동시에 실행될 수 없음을 보입니다.
이 그림처럼 어떤 프로세스를 실행중 (5000~) Time out으로 타이머 인터럽트를 만나게 되면 해당 인터럽트 서비스 루틴 (100~)으로 넘어가게 되고, 스케줄러는 어떤 우선순위에 따라 다음 프로세스 (8000~)로 넘어갑니다. 또 I/O request의 입출력 인터럽트를 만나게 되면 해당 인터럽트 서비스 루틴으로… 해당 과정이 반복됩니다. 그러면서 우리는 프로그램을 동시에 실행시키는것처럼 보이게 됩니다.
프로세스 생성
프로세스는 생성과 종료가 가능합니다. 우선 시스템이 작동할때 실행되는 가장 첫 번째의 프로세스 (최초의 프로세스)가 존재합니다. 유의할 것은 최초의 프로세스를 제외하고서는 모두 부모 프로세스에 의해서 만들어집니다. 그러한 자식 프로세스는
- 실행되는 프로세스의 콜에 의해 생성되거나
- 사용자가 새로운 프로세스를 요청하거나
- 어떤 프로그램의 작업에서 프로세스를 생성할 수 있습니다.
예를 들면 GUI에서 아이콘을 클릭해 프로세스를 생성한다고 할 때, GUI(부모) -> 어떤 프로세스(자식) 이러한 관계가 Tree처럼 만들어집니다.
프로세스 종료
모든 프로그램의 마지막에는 exit를 호출하게 되어있습니다. 그런데 이러한 exit에도 종류가 있습니다.
- 일반적인 종료 (Normal exit로, 자발적입니다.)
- 에러 종료 (Error exit로, 자발적입니다.)
- 치명적 에러 (Fatal error로, 비자발적입니다.) 보통 운영체제에 의해서 생깁니다. 0으로 나누거나, 허가되지 않은 메모리 영역 등..
- 다른 프로세스에 의해 종료 (비자발적입니다.)
프로세스 상태
모든 프로세스는 상태가 존재합니다. 기본적으로는 실행중(running), 차단(blocked), 준비(ready) 가 있습니다.
- 어떤 프로세스가 입출력(인터럽트) 상태일 때, 그 프로세스를 차단 상태로 바꿉니다.
- 스케줄러는 그 프로세스가 아닌 다른 프로세스를 작동시킵니다.
- 입출력이 끝나면, 그 프로세스는 ready로 바뀌어 다시 실행 가능해집니다.
그런데 이 기본적인 세 가지 말고도 중단(suspend) 상태가 추가되는데, 이 상태는 시스템 혹은 사용자가 의도적으로 어떤 프로세스를 중단시킨 것입니다.
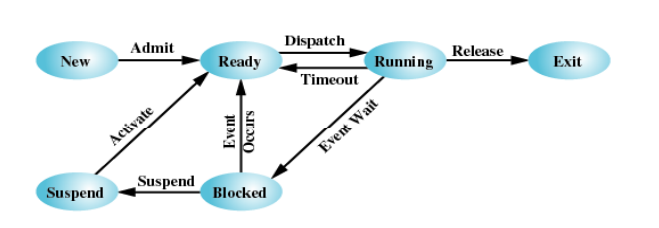
다음 그림을 보면, 프로세스가 차단된 상태에서 의도적으로 중단될 수 있습니다. 다시 이 프로세스를 활성화하면 준비 상태로 바뀌게 됩니다. 하지만 이 경우를 생각해 볼 수 있습니다.
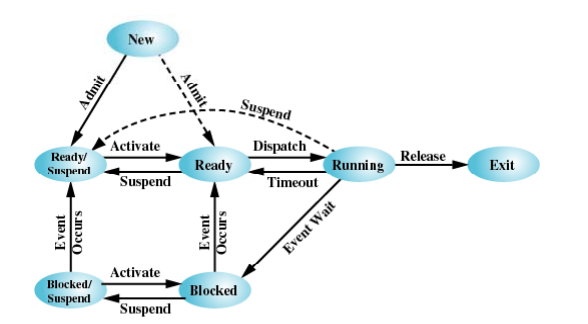
이 경우 중단 상태의 종류가 두 가지입니다. 준비 상태에서 중단된 것과, 차단 상태에서 중단된 것이 있습니다. 어떤 상태에서 중단되었는지에 따라 활성화되었을때 상태가 다릅니다.
프로세스의 구현
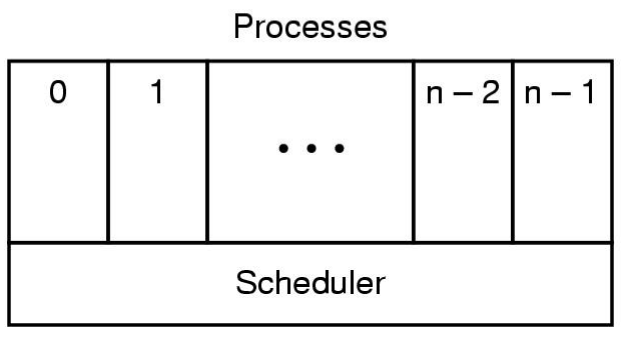
운영체제의 프로세스 구조 레이어의 최하단에는 인터럽트를 관리하고 스케줄링을 수행합니다. (이때 스케줄러는 프로세스가 아닙니다.) 그리고 그 레이어의 위에는 연속적으로 프로세스가 존재합니다.
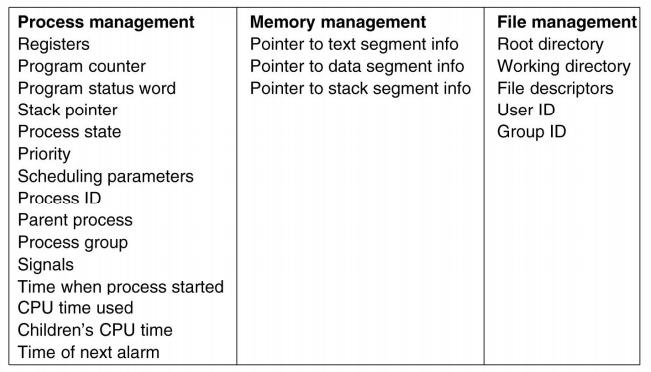
프로세스 테이블이라는 것이 있는데, 프로세스를 관리하기 위한 자료구조와 같은 것들이 정의되어 있는 테이블입니다. 프로세스 관리를 위한, 메모리 관리를 위한, 파일 관리를 위한 자료구조들이 있습니다.
만약 프로세스에 인터럽트가 발생하면 일단 현재 실행중인 명령어까지는 마칩니다. 그 다음 진행과정은 다음과 같습니다.
- 스택 (SP라고도 합니다.)에 현재 프로그램 카운터 (PC)의 값을 저장합니다.
- 인터럽트 벡터로부터 인터럽트의 주소값을 받아 PC에 저장합니다.
- 현재 레지스터들의 정보를 저장합니다.
- 새로운 스택 (시스템 호출이므로 유저 스택이 아니고 커널 스택입니다.)을 셋업합니다.
- 인터럽트 서비스를 수행합니다.
- 스케줄러가 다음 프로세스를 결정합니다. 이때 다음 프로세스는 꼭 이전 프로세스가 아닐 수 있습니다. 우선 순위에 따라 달라집니다.
여기서 원래 프로세스로 돌아갈 때는 역순으로, 즉 4->3->2->1 순으로 돌아갑니다.
멀티프로그래밍 모델링
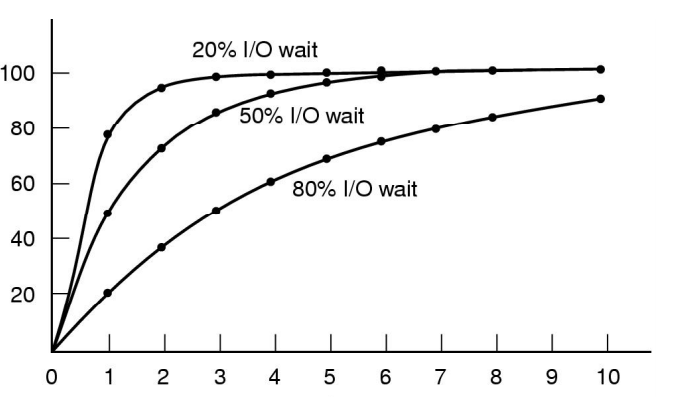
다음 그래프는 x축이 메모리에 적재한 프로세스의 수, y축이 CPU의 사용률을 의미합니다. 사용자 입장에서는 CPU 사용률이 100퍼센트에 가까울수록 좋겠죠. 시간대비 효율적으로 연산을 수행할 수 있으니까요.
그런데 이 그래프를 보면 I/O를 적게 사용하는 경우 (프로세스의 약 20%의 I/O 대기) 두 개의 프로세스를 번갈아가며 사용해도 CPU 활용도가 100%에 가까운데, 50%, 80%만 가더라도 활용도가 많이 떨어지는 것을 볼 수 있습니다. 특히나 현재처럼 GUI인터페이스를 사용하는 경우 I/O 대기시간이 매우 깁니다. 다양한 방법으로 들어오는 사용자의 입력을 항상 기다려야 하기 때문이지요. 이를 보면 메모리에 적재한 프로세스의 수가 많으면 많을 수록 좋겠지만, 메모리의 한계로 아주 많이 적재할 수는 없는 실정입니다. 그래서 쓰레드라는 개념을 만들게 됩니다.